一次网络请求
目前我们的网络框架采用RxJava+Retrofit+OkHttp,使用起来非常简单,只需要简单几行代码便能完成整个网络请求
retrofit.create(serviceClass) |
这些高度封装的第三方库内部却不是这么简单,我们就跟随一条简单的网络一起探索一下这个全过程。
Retrofit
网络请求的开始从Retrofit开始,Retrofit的核心是动态代理,通过注解和返回值来创建Restful的网络请求。所以Retrofit的核心代码不算太多,从我们通过create创建了网络请求的代理类开始
public <T> T create(final Class<T> service) { |
在loadServiceMethod中有大量逻辑都是处理Retrofit的注解生成相应网络请求Request的过程(这个不是本文的重点),同时还会获得两个比较重要的对象 CallAdapter 和 Converter ,这两个对象都是用于在请求过程中对于网络请求的结果进行转换,但是两者的作用不同
Converter主要用于值转换,可以自定义将原始的ResponseBody转换成String或者其他对象,一般用于Gson解析CallAdapter用于将Call转换成其他对象,Call对象本身是一个接口,Retrofit的主要实现类是OkHttpCall,这个是OkHttp中RealCall的封装类
这个两个对象在实际流程中的关系如下
ResponseBody -> Converter -> T |
ResponseBody 经过 Converter 转换后的类型回作为Call对象范型类型,然后通过 CallAdapter 转换成其他类型。
这两个对象都是通过抽象工厂模式来创建,我们可以添加抽象工厂来自定义这两个对象,Converter 和CallAdapter 中具体工厂都是根据他们的返回值类型来确定的,首先确定是 CallAdapter 的工厂,然后根据 CallAdapter.adapt 方法的入参Call的范型类型确定 Converter
##OkHttp
OkHttpClient 的创建和RealCall 的创建过程就不多做介绍了,我们从RealCall的execute 和 enqueue 两个方法开始。
public Response execute() throws IOException { |
可以看到这两个方法一个是同步请求,一个是异步请求,但是在1和3处都使用到了 Dispatcher 这个对象,同时同步请求回在2处直接调用 getResponseWithInterceptorChain 执行请求,我们先看一下 Dispatcher 这个对象的几个重要成员。
/** Executes calls. Created lazily. */ |
可以看到 Dispatcher 中有三个队列以及一个 Executor ,而这个 Executor 事实上是一个线程池,从变量命名上看 Dispatcher 的实现已经很明显了
- 一个异步请求的等待队列
- 一个异步请求的执行队列
- 一个同步请求的执行队列
- 一个异步请求的线程池
在前面的代码中我看到在执行异步请求时会把 RealCall 封装在 AsyncCall 内,我们看一下 AsyncCall 的execute方法
protected void execute() { |
可以看到异步请求最终也是调用了 getResponseWithInterceptorChain 方法来执行最终的请求,OkHttp可以分为两段,而这个方法是下半段的开始,也是OkHttp请求的核心。
Response getResponseWithInterceptorChain() throws IOException { |
在OkHttp中使用拦截器链来进行网络请求,且内置了五个拦截器,在查看这五个拦截器之前,我们先看一下拦截器链的结构
//RealInterceptorChain.java |
可以看到 RealInterceptorChain 每执行一个拦截器都会创建一个新的 RealInterceptorChain 对象,同时通过index控制目前使用的拦截器,并调用拦截器的 intercept 方法。
RetryAndFollowUpInterceptor
在这个拦截器内主要做了两件事
- 创建了StreamAllocation对象,这个对象在后面再详细介绍
- 根据网络请求的相应错误码比如301、408,进行重试
public Response intercept(Chain chain) throws IOException { |
BridgeInterceptor
主要是对请求头和响应头的处理,比如添加一些Content-Length,Content-Type 等通用的请求头,同时cookie、请求体和响应体gzip压缩和解压的处理也是在这个拦截器
public Response intercept(Chain chain) throws IOException { |
这个地方第一次出现了Source,这个是OkIo中定义的对象,是IO流的封装类,后面详细介绍
CacheInterceptor
CacheInterceptor 的意义从名称上来看来已经很明显了,但是这个Okhttp的实现可能和我们想象中的不一 样,CacheInterceptor 主要针对的是304 HTTP_NOT_MODIFIED 响应码,一般正常的网络请求都会正常进行,但是会在后台返回304时,使用本地缓存
CacheInterceptor 主要关注什么样的请求响应需要被缓存和缓存的时常(这往往取决于Http的头部信息),具体的缓存使用 DiskLruCache 来实现,但是OkHttp对于 DiskLruCache 底层IO使用OkIO重写了,有兴趣的可以自行研究
Okhttp中前三个拦截器都是相对比较容易理解的,但是从第四个拦截器开始,负责度就开始提升了,这个原因主要有两个
- 从第四个拦截器开始,OkIO的相关代码开始大量出现,提高了代码复杂度
- OkHttp实现了Http2.0协议,从这里开始有很多Http2.0的实现代码(这个也是OkHttp相较于早期其他比如HttpClient和HttpUrlConnection网络请求框架一个巨大的提升,不过目前HttpUrlConnection底层已经替换为OkHttp了)
Okio
Okio 是对于JavaIO的一次封装,主要整合了家族庞大的JavaIO,使用统一的Sink(相当于OutputStream)和Source(相当于InputStream)来处理各种不同类型的输入和输出,同时提供Buffer缓存机制。
这个为了OkHttp整体流程的连贯性,作为OkHttp的一节,但是OkIO是一个独立的框架,我们完全可以使用把它用于各种的IO场景中。
Buffer缓存机制
整个Buffer缓存机制主要有三个对象组成
- Segment Buffer缓存的最小单位
- Buffer 由Segment组成的双向链表,使用链表结构可以大量避免
System.arraycopy - SegmentPool Segment缓存池,回收复用Segment内存,避免内存分配的消耗
Segment
Segment 本质上就是一个定长的字节数组,包括一个指向数据头部的指针,一个指向数据尾部的指针,同时定义了一些在这个结构上的方法,比如split 、 compact 、writeTo
Buffer
Buffer 同时实现了BufferedSink 和 BufferedSource ,也就是说Buffer 既可以作为输入流从中获取数据,也可以作为输出流向外输出数据,本质上它就是一个缓冲区,同时它内部使用Segment 的双向链表来存储数量,使得在 Buffer 间传递数据时可以直接通过修改Segment 的链表指针来完成,大量减少了 System.arraycopy 的消耗,我们可以通过几个代表性的方法来了解一下 Buffer
将Buffer写入到输出流 |
可以看到将 Buffer 写入到OutputStream 时,事实上就是将每一个 Segment 的内容写入到 OutputStream 中,同理将其他数据写入 Buffer 时也是类似的,就是将数据写入到 Segment 中。
在 Buffer 中提供了很多中不同的读和写的方法,同时还提供了内置的加密方式。
SegmentPool
由 Segment 组成的单链表缓存区,对外提供两个静态方法take ,recycle 用于回收和获取 Segment 。
Okio的家族体系
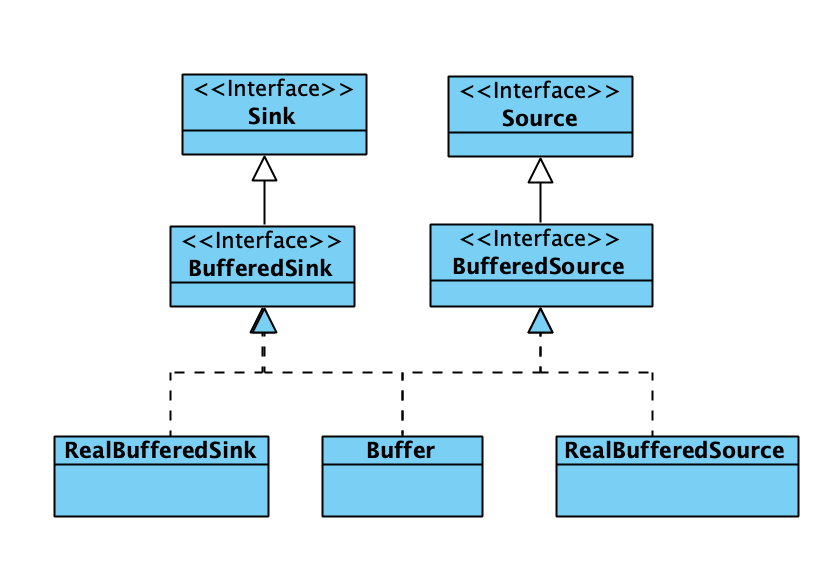
Okio 中的主要对象只有上面几个,其中的缓存都以Buffer为核心,除了上述几个对象外还有很多其他是以内部类的形式存在的 Sink 和 Buffer ,例如在 Okio 这个入口类中提供了很多 sink 和 Buffer 的方法用于将Okio 对接到传统IO上,这个实现也是通过创建 Sink 和 Buffer 的内部类来完成的
private static Source source(final InputStream in, final Timeout timeout) { |
Http2.0
http2.0协议标准于2015年5月以RFC 7540正式发表, 在介绍http2.0之前我们先看下http协议的发展的几个阶段
- http/1.x 一次只允许在一个TCP连接上发起一个请求,单向,只能由客户端发起,数据未压缩
- SPDY 支持多路复用(Tcp连接复用),header压缩,强制使用https加密传输,服务端推送
- http/2.0 支持明文和加密传输,优化了header压缩算法,支持SDPY现有功能
- Quic 基于UDP的稳定传输协议
Http2.0连接过程
HTTP/2协议在TCP连接之初进行协商通信,只有协商成功,才会涉及到后续的请求-响应等具体的业务型数据交换。
Http2.0明文连接的主要过程如下:
客户端发起请求,只有请求报头,携带
Upgrade相关头部信息,用于试探服务器是否支持Http2.0GET / HTTP/1. 1
Host: server. example. com
Connection: Upgrade, HTTP2-Settings
Upgrade: h2c
HTTP2-Settings: <base64url encoding of HTTP/2 SETTINGS payload>服务器支持HTTP/2,则通知客户端切换到HTTP/2
HTTP/1. 1 101 Switching Protocols
Connection: Upgrade
Upgrade: h2c
[ HTTP/2 connection . . .101响应空行之后,服务器必须发送的第一个帧为SETTINGS帧(其负载可能为空)作为连接序言
客户端接收到101响应后,也必须发送一个序言作为响应,其逻辑结构如下
PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n // 纯字符串表示,翻译成字节数为24个字节
SETTINGS帧 // 其负载可能为空服务器端和客户端所发送的连接序言有所不同。
客户端可以马上发送请求帧或其它帧过去,不用等待来自服务器端的SETTINGS帧
任一端接收到SETTINGS帧之后,都需要返回一个包含确认标志位SETTIGN作为确认
其它帧的正常传输
其他连接建立过程大家可以自行查阅。
HTTP/2 帧
HTTP/2下终端之间使用帧的数据形式进行数据交换,一个标准的帧的格式如下
+-----------------------------------------------+ |
HTTP/2下有多种类型的帧,帧的类型由Type指定,具体类型下的一些标志位由Flags指定,我们上文提到的SETTINGS帧则是HTTP/2所支持的帧的一种。对HTTP/2有兴趣的可以查阅RFC 7540 以及相关技术文档
ConnectInterceptor
ConnectInterceptor 主要用于创建和复用TCP连接,拦截器中的主要代码就一行
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks); |
最终的核心代码在 StreamAllocation 中
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout, |
获取TCP连接的部分比较复杂,核心代码有5处,1和3都是尝试从 ConnectionPool 连接池中获取连接,4是在没有可复用的连接情况下创建了一个新的 RealConnection 对象,5是使用 RealConnection 进行网络连接,我们先看一下1和3到底有什么区别,他们最大的区别就在于第一次没有Route参数,第二次遍历了一个Route列表,传入Route参数。
Route
Route 从命名上看起来很像IP层中的路由,其实不然,它可能代表了代理或者一个IP。
通常我们都是通过域名访问网络,但是事实上我们无法直接通过域名访问到服务器,首先需要通过DNS将域名解析到IP之后我们通过IP来访问资源,在 OkHttp 中这个过程通过DNS这个类来完成
Dns SYSTEM = new Dns() { |
OkHttp 默认使用 InetAddress 来完成域名解析,这个类是java网络包下用于完成DNS解析的类,具体DNS解析过程大家有兴趣可以自行查阅。域名通过DNS解析之后会返回一个列表,因为可能域名对应了多个ip,随后这些ip会被封装成一个个Route 对象,这个过程由上节2处的 routeSelector.next 触发。
public Selection next() throws IOException { |
了解完Route的概念我们再回头来看 ConnectionPool 的get方法
RealConnection get(Address address, StreamAllocation streamAllocation, Route route) { |
方法会遍历所有空闲的 RealConnection ,通过 isEligible 判断连接可用之后则会复用连接。
public boolean isEligible(Address address, @Nullable Route route) { |
复用连接的条件在注释写的很清楚了
- 当前连接承载已经到了上限或者
noNewStreams,则无法复用 - 当Address中除了域名外其他信息比如协议、端口等相关信息有不相同的则无法复用
- 通过上述条件后,域名相同可以直接复用
- 域名不同情况,需要满足如下条件才能复用
- 当前连接和要创建的连接代理类型均为直接连接
- ip地址相同
- 当前连接的ssl证书必须包括新的ip
- ssl-Pinner验证要通过
连接复用的部分到此结束。
连接过程
当无法复用连接时,会创建新的 RealConnection 并开始连接过程
public void connect(int connectTimeout, int readTimeout, int writeTimeout, |
核心代码主要有两处:
建立socket连接
private void connectSocket(int connectTimeout, int readTimeout, Call call,
EventListener eventListener) throws IOException {
Proxy proxy = route.proxy();
Address address = route.address();
rawSocket = proxy.type() == Proxy.Type.DIRECT || proxy.type() == Proxy.Type.HTTP
? address.socketFactory().createSocket()
: new Socket(proxy);
eventListener.connectStart(call, route.socketAddress(), proxy);
//设置连接超时长
rawSocket.setSoTimeout(readTimeout);
try {
//连接socket
Platform.get().connectSocket(rawSocket, route.socketAddress(), connectTimeout);
} catch (ConnectException e) {
ConnectException ce = new ConnectException("Failed to connect to " + route.socketAddress());
ce.initCause(e);
throw ce;
}
try {
//获取输入输出流,使用Okio进行封装
source = Okio.buffer(Okio.source(rawSocket));
sink = Okio.buffer(Okio.sink(rawSocket));
} catch (NullPointerException npe) {
if (NPE_THROW_WITH_NULL.equals(npe.getMessage())) {
throw new IOException(npe);
}
}
}确定传输协议(HTTP/1.1或者HTTP/2)
establishProtocol这里会确认传输协议,具体有三种情况- HTTP/1.1协议
- HTTP/2明文传输(h2c)
- HTTP/2加密传输(h2)
如果是HTTP/1.1协议则连接建立完成,如果是HTTP/2协议,则会开始HTTP/2 的连接建立过程,如果是HTTP/2加密传输还会先开始TLS握手过程
private void connectTls(ConnectionSpecSelector connectionSpecSelector) throws IOException {
Address address = route.address();
SSLSocketFactory sslSocketFactory = address.sslSocketFactory();
boolean success = false;
SSLSocket sslSocket = null;
try {
// Create the wrapper over the connected socket.
sslSocket = (SSLSocket) sslSocketFactory.createSocket(
rawSocket, address.url().host(), address.url().port(), true /* autoClose */);
// Configure the socket's ciphers, TLS versions, and extensions.
ConnectionSpec connectionSpec = connectionSpecSelector.configureSecureSocket(sslSocket);
if (connectionSpec.supportsTlsExtensions()) {
Platform.get().configureTlsExtensions(
sslSocket, address.url().host(), address.protocols());
}
// Force handshake. This can throw!
sslSocket.startHandshake();
// block for session establishment
SSLSession sslSocketSession = sslSocket.getSession();
Handshake unverifiedHandshake = Handshake.get(sslSocketSession);
// Verify that the socket's certificates are acceptable for the target host.
if (!address.hostnameVerifier().verify(address.url().host(), sslSocketSession)) {
X509Certificate cert = (X509Certificate) unverifiedHandshake.peerCertificates().get(0);
throw new SSLPeerUnverifiedException("Hostname " + address.url().host() + " not verified:"
+ "\n certificate: " + CertificatePinner.pin(cert)
+ "\n DN: " + cert.getSubjectDN().getName()
+ "\n subjectAltNames: " + OkHostnameVerifier.allSubjectAltNames(cert));
}
// Check that the certificate pinner is satisfied by the certificates presented.
address.certificatePinner().check(address.url().host(),
unverifiedHandshake.peerCertificates());
// Success! Save the handshake and the ALPN protocol.
String maybeProtocol = connectionSpec.supportsTlsExtensions()
? Platform.get().getSelectedProtocol(sslSocket)
: null;
//ssl验证通过,使用sslSocket替代当前socket
......
} catch (AssertionError e) {
......
} finally {
......
}
}整个握手过程可以分为如下几个步骤
- 通过sslSocketFactory获取sslSocket,这个是使用TLS加密层封装过的socket
- 设置参数TSL参数
- TSL握手和hostnameVerifier校验,这个是标准的TLS验证过程
- ssl-pinner校验
TLS和SSL其实是两种协议,但是TLS建立在SSL3.0之上,是SSL3.0的后续版本,甚至TLS1.0在某种意义上都可以为称为SSL3.1,目前SSL协议已经基本被废弃,转而使用TLS,但是习惯上会使用TLS/SSL协议
之后便正式开始HTTP/2的连接过程,此时会创建一个
Http2Connection对象,并调用它的start方法void start(boolean sendConnectionPreface) throws IOException {
if (sendConnectionPreface) {
writer.connectionPreface();
writer.settings(okHttpSettings);
int windowSize = okHttpSettings.getInitialWindowSize();
if (windowSize != Settings.DEFAULT_INITIAL_WINDOW_SIZE) {
writer.windowUpdate(0, windowSize - Settings.DEFAULT_INITIAL_WINDOW_SIZE);
}
}
new Thread(readerRunnable).start(); // Not a daemon thread.
}前面在介绍HTTP/2协议在开始会发送
Upgrade试探服务器是否支持HTTP/2,但上述代码中其实没有这个步骤,这个是因为此时已经确定使用 HTTP/2协议,所以省略了这个步骤,直接开始发送连接序言,而后发送SETTINS帧,同时会开启线程接受服务端的连接序言以及后续帧。
CallServerInterceptor
在理解HTTP/2和OKIO的前提下,CallServerInterceptor 的内容其实已经不难理解了,首先在 CallServerInterceptor 时,HTTP/2的连接已经完成,开始正式的数据交换
public Response intercept(Chain chain) throws IOException { |
整个过程可以分为几个部分
- 请求头发送
- 请求体的发送
- 响应头的读取
- 响应体的读取
Header的封装和传输
头部的传输从 httpCodec.writeRequestHeaders 开始,这里针对HTTP/1.1和HTTP/2有一定的区分,HTTP/1.1会直接将头部信息写入Sink ,也就是Okio的输出流中,对于HTTP/2中这个行为将有所不同,在HTTP/2会调用 Http2Connection.newStream 方法
public Http2Stream newStream(List<Header> requestHeaders, boolean out) throws IOException { |
这里会创建一个 Http2Stream ,这个其实是一个抽象的概念,内部封装了HTTP/2请求中双向流的概念,同时会调用 writer.synStream ,最终会调用 Http2Writer.headers 方法,
void headers(boolean outFinished, int streamId, List<Header> headerBlock) throws IOException { |
这里有两个关键的点
- HTTP/2头部压缩,hpackWriter所在Hpack类就是HTTP用于头部压缩的类
- HTTP帧的概念,这个也在前面有提过,这里开始真正应用了
Hpack
Hpack就是HTTP/2引入的新的头部压缩方案,在此之前主要的头部压缩算法是deflate算法(一种主要基于哈夫曼编码和 LZ77压缩的算法),主要做的还是单纯的字符串压缩,Hpack压缩主要有三种压缩方法
- 静态字典:一个有着 61 个通用头部字段,并且部分字段是有预定义值的预定义字典。
- 动态字典:在连接中,一系列实际的头部会被添加进去。因为字典有限制大小,所以当新项被增加,旧项会被去除。
- Huffman 编码: 一种可以被用来对任何字符串:键或者值(译者注:下文 name 对应键,value 对应值),进行编码的静态 Huffman 编码。这种编码方式是专门为 HTTP 响应或者响应头部设计的——ASCII 里的数字和小写字母可以编码地更短,最短可以编码为 5 个比特(bits)。因此最高压缩比可以达到 8:5 (也就是最多可以降低 37.5%)。
OkHttp中的Hpack类就是这个算法的实现类,最终压缩之后的头部会写入到一个Buffer缓冲区中,然后通过 frameHeader 方法来为Header信息添加帧的头部信息,同时确定Header的长度是否需要分帧,因为在HTTP/2中帧的大小是有限制的,这个限制由服务端的SETTINGS帧和默认的帧大小(如果还没有收到SETTINGS帧)来确定。
到此 为止 CallServerInterceptor 也没有太多陌生的东西的,剩余的基本就是对 Source 和 Sink 的封装以及各种IO操作了。
Title:网络连接过程 |
Title:网络请求过程 |
RxJava
rxjava在网络请求的过程中主要两个地方:
- 前面说到过的Retrofit 中的
CallAdapter,这里我们有一个Rxjava专用的CallAdapter - Rxjava强大现场转换功能
我们关注的也仅限于这两点,其他操作符,大家可以自行研究
RxJava2CallAdapterFactory
前面说到 CallAdapter 是通过抽象工厂模式创建的,RxJava2CallAdapterFactory 就是一个CallAdapter 的具体工厂。
在开始之前我们先了解反射的相关知识,此处对于 Class 对象以及相关操作就不多做介绍,这里主要针对有泛型的情况。
泛型擦除与反射
我们知道Java有泛型擦除的机制,但是编译之后真的就没有泛型的概念了吗?考虑如下代码
public class Test<T extends String>{ |
上述代码经过编译和反编译还会保留什么信息?下面是编译完再反编译之后的代码
public class Test<T extends String> extends Object { |
可以看到部分泛型确实以及被擦除了,但是定义在类上,成员变量以及方法上的泛型都保留了,我们回头看一下 Class 类的定义
public final class Class<T> implements java.io.Serializable, |
可以看到 Class 实现了Type 接口,反射包下的 Type 接口就是类型的抽象,除了 Class 他还有几个其他的实现
- ParameterizedType 带参数的类型,即泛型,如:
List<T>、Map<Integer, String> - GenericArrayType (泛型)数组类型,比如
List<T>[],T[]这种 - WildcardType 代表通配符表达式,或泛型表达式,比如
?, ? super T - TypeVariable 类型变量,描述类型,表示泛指任意或相关一类类型,比如
K、V、E等
抽象工厂
CallAdapter.Factory 作为 CallAdapter 工厂的抽象类,它定义获取创建 CallAdapter 的抽象方法
public abstract CallAdapter<?> get(Type returnType, Annotation[] annotations, |
可以看到第一个入参就是我们上节提到的 Type 类型,这个对象通过 Method.getGenericReturnType 返回,这个是一个携带范型信息的类型。
RxJava2CallAdapterFactory 实现的get方法如下
public CallAdapter<?> get(Type returnType, Annotation[] annotations, Retrofit retrofit) { |
整段代码逻辑基本上可以分为2个部分
- 获取原始类型,过滤掉非RxJava支持的原始类型
- 获取范型类型,过滤掉没有上界的范型类型
RxJava2CallAdapter 的实现相对就比较简单了,就是将 Call 封装成 Observable ,这里根据上面范型类型的不同会有三种 Observable ,但是没有本质的区别,只是对结果的不同封装,有兴趣可以自行了解。
线程变换
Scheduler调度器
在Rxjava的线程变换中 Scheduler 占据的很大分量,在Rxjava中的几个线程变换的方法也是基于Scheduler来完成的,我们首先来看下 Scheduler 的定义。
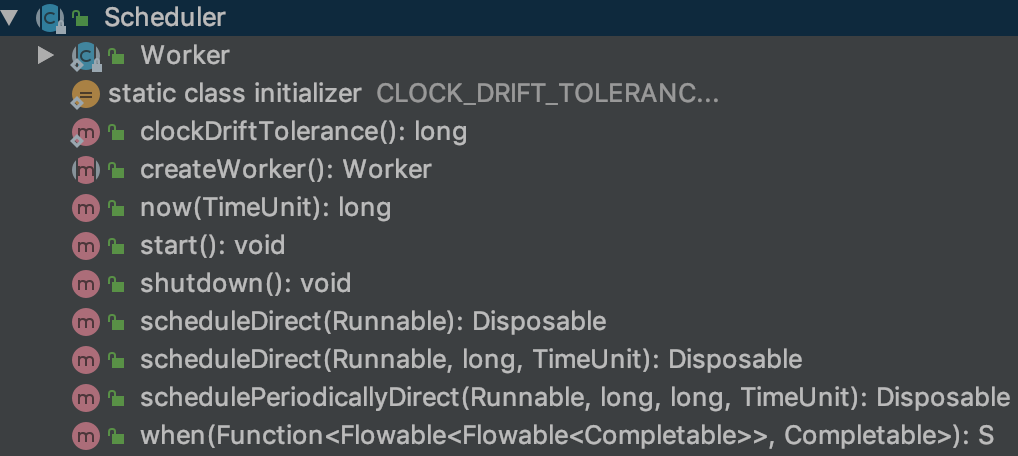
可以看到 Scheduler 下的方法不多,还有一个内部类,这些方法基本可以分为三类
工具方法,没有太多逻辑,这里不多做介绍
模版方法,入参都以
Runnable为主scheduleDirect直接在Scheduler指定的线程在对Runnable调度schedulePeriodicallyDirect在Scheduler所指定线程周期性的执行Runnable
需要子类实现的方法
createWorker用于创建Worker,Worker继承自Disposable,熟悉RxJava的同学应该知道,这个用于表示一次性用品,当dispose调用后Disposable的工作就终止了 ,而Worker主要是Runnable的执行体start一般用于以线程池实现的Scheduler, 用于开始线程池shutdown一般用于结束线程池
首先我们先看下 Scheduler 下的主要模版方法 scheduleDirect
public Disposable scheduleDirect(Runnable run, long delay, TimeUnit unit) { |
可以看到scheduleDirect 的主要工作是通过 Worker 来完成的,而 Worker 的实现主要又依赖于它的实现类。接下来我们以IoScheduler 为例,来了解 Scheduler 实现。
static { |
可以看到IoScheduler类中本身也没有太多的逻辑,核心的逻辑主要还是由 EventLoopWorker 这个 Worker 的实现类来完成的,在开始之前我们需要先了解一下 IoScheduler 的特点,它主要为 IO 密集型设计,IO 密集型的特点就是大量时间在等待磁盘,一定范围内,任务越多,性能越好。
EventLoopWorker 在构造函数中会从 CachedWorkerPool 中获取 Worker
ThreadWorker get() { |
可以看到CachedWorkerPool 其实就是一个 Worker 池,他会回收和复用 Worker ,ThreadWorker 继承自NewThreadWorker ,主要扩展了超时的概念,实际的逻辑在父类中实现
public NewThreadWorker(ThreadFactory threadFactory) { |
NewThreadWorker 的构造函数会创建一个线程池,创建的线程池是ScheduledThreadPoolExecutor ,这个是一个线程数量无限制,且可以执行延迟任务和周期任务的线程池,具体实现大家自行查阅,NewThreadWorker 的 schedule 主要也是依赖这个线程池
public Disposable scheduleDirect(final Runnable run, long delayTime, TimeUnit unit) { |
线程变换方法
我们首先以 subscribeOn 为例来了解这个过程
public final Observable<T> subscribeOn(Scheduler scheduler) { |
subscribeOn 主要是创建了一个新的Observable ,我们主要来看一下它的subscribeActual ,这个是我们订阅时最终调用的方法。也就是当subscribeOn 生成的Observable 方法的subscribe 被调用时调用的方法
|
可以看到核心代码在最后一行我们使用Scheduler去调度一个Runnable ,以IOScheduler 为例,他会使用一个ScheduledThreadPoolExecutor的线程池来执行这个Runnable,也就是这个Runable 最终是在一个线程池中运行的。
final class SubscribeTask implements Runnable { |
这个 Runnable 的实现也非常简单,但是也是 Rxjava 操作符的核心,链式操作。